Table of Contents
![]()
Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS. | ||
| -- Apache HBase Homepage | ||
The following sections outline the various ways in which JanusGraph can be used in concert with Apache HBase.

HBase can be run as a standalone database on the same local host as JanusGraph and the end-user application. In this model, JanusGraph and HBase communicate with one another via a localhost socket. Running JanusGraph over HBase requires the following setup steps:
- Download and extract a stable HBase from http://www.apache.org/dyn/closer.cgi/hbase/stable/.
- Start HBase by invoking the
start-hbase.shscript in the bin directory inside the extracted HBase directory. To stop HBase, usestop-hbase.sh.
$ ./bin/start-hbase.sh starting master, logging to ../logs/hbase-master-machine-name.local.out
Now, you can create an HBase JanusGraph as follows:
JanusGraph graph = JanusGraphFactory.build() .set("storage.backend", "hbase") .open();
Note, that you do not need to specify a hostname since a localhost connection is attempted by default. Also, in the Gremlin Console, you can not define the type of the variables conf and g. Therefore, simply leave off the type declaration.
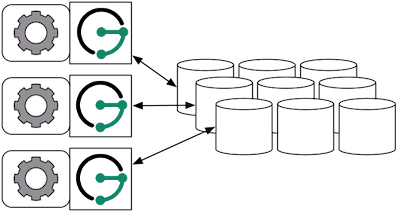
When the graph needs to scale beyond the confines of a single machine, then HBase and JanusGraph are logically separated into different machines. In this model, the HBase cluster maintains the graph representation and any number of JanusGraph instances maintain socket-based read/write access to the HBase cluster. The end-user application can directly interact with JanusGraph within the same JVM as JanusGraph.
For example, suppose we have a running HBase cluster with a ZooKeeper quorum composed of three machines at IP address 77.77.77.77, 77.77.77.78, and 77.77.77.79, then connecting JanusGraph with the cluster is accomplished as follows:
JanusGraph g = JanusGraphFactory.build() .set("storage.backend", "hbase") .set("storage.hostname", "77.77.77.77, 77.77.77.78, 77.77.77.79") .open();
storage.hostname accepts a comma separated list of IP addresses and hostname for any subset of machines in the HBase cluster JanusGraph should connect to. Also, in the Gremlin Console, you can not define the type of the variables conf and g. Therefore, simply leave off the type declaration.
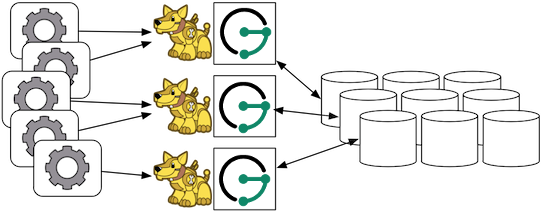
Finally, Gremlin Server can be wrapped around each JanusGraph instance defined in the previous subsection. In this way, the end-user application need not be a Java-based application as it can communicate with Gremlin Server as a client. This type of deployment is great for polyglot architectures where various components written in different languages need to reference and compute on the graph.
http://gremlin-server.janusgraph.machine1/mygraph/vertices/1
http://gremlin-server.janusgraph.machine2/mygraph/tp/gremlin?script=g.v(1).out('follows').out('created')In this case, each Gremlin Server would be configured to connect to the HBase cluster. The following shows the graph specific fragment of the Gremlin Server configuration. Refer to Chapter 7, JanusGraph Server for a complete example and more information on how to configure the server.
...
graphs: {
g: conf/janusgraph-hbase.properties}
plugins:
- janusgraph.imports
...Refer to Chapter 13, Configuration Reference for a complete listing of all HBase specific configuration options in addition to the general JanusGraph configuration options.
When configuring HBase it is recommended to consider the following HBase specific configuration options:
- storage.hbase.table: Name of the HBase table in which to store the JanusGraph graph. Allows multiple JanusGraph graphs to co-exist in the same HBase cluster.
Please refer to the HBase configuration documentation for more HBase configuration options and their description. By prefixing the respective HBase configuration option with storage.hbase.ext in the JanusGraph configuration it will be passed on to HBase at initialization time. For example, to use the znode /hbase-secure for HBase, set the property: storage.hbase.ext.zookeeper.znode.parent=/hbase-secure. The prefix allows arbitrary HBase configuration options to be configured through JanusGraph.
| Important | |
|---|---|
HBase backend uses millisecond for timestamps. In JanusGraph 0.2.0 and earlier, if the |
JanusGraph over HBase supports global vertex and edge iteration. However, note that all these vertices and/or edges will be loaded into memory which can cause OutOfMemoryException. Use Chapter 35, JanusGraph with TinkerPop’s Hadoop-Gremlin to iterate over all vertices or edges in large graphs effectively.
Amazon EC2 is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers. | ||
| -- Amazon EC2 | ||
Follow these steps to setup an HBase cluster on EC2 and deploy JanusGraph over HBase. To follow these instructions, you need an Amazon AWS account with established authentication credentials and some basic knowledge of AWS and EC2.
The following commands first launch a four-node HBase cluster on EC2 via Whirr, then run a basic JanusGraph test case using the cluster.
The configuration described below puts one HBase master server in charge of three HBase regionservers. The master will be the sole member of the Zookeeper quorum by which JanusGraph connects to HBase.
Whirr 0.7.1 sometimes fails when run on a machine behind a NAT WHIRR-459. For this reason, it’s recommended to use at least Whirr 0.7.2. Whirr 0.8.0 was used to test the following commands on a t1.micro instance running Amazon Linux 2012.03. These commands might need tweaking to produce the intended results on environments besides a t1.micro instance running Amazon Linux 2012.03.
# These commands were executed on a t1.micro instance running Amazon Linux 2012.03 x86_64. # The AMI identifier for Amazon Linux 2012.03 x86_64 is ami-aecd60c7. # https://console.aws.amazon.com/ec2/home?region=us-east-1#launchAmi=ami-aecd60c7 export AWS_ACCESS_KEY_ID=... # Set your Access Key here export AWS_SECRET_ACCESS_KEY=... # Set your Secret Key here curl -O http://www.apache.org/dist/whirr/whirr-0.8.0/whirr-0.8.0.tar.gz tar -xzf whirr-0.8.0.tar.gz && cd whirr-0.8.0 # Generate an SSH keypair with which Whirr will deploy and manage instances ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa_whirr # Download a Whirr recipe for deploying HBase 0.94.1 with hadoop-core 1.0.3 pushd recipes && wget 'https://raw.github.com/JanusGraph/janusgraph/master/config/whirr-hbase.properties' ; popd bin/whirr launch-cluster --config recipes/whirr-hbase.properties --private-key-file ~/.ssh/id_rsa_whirr # Run a superficial health check on the hbase-master node (this should print "imok") echo "ruok" | nc $(awk '{print $3}' ~/.whirr/hbase-testing/instances | head -1) 2181; echo # Login to the HBase master node to run the remaining commands ssh -i ~/.ssh/id_rsa_whirr -o "UserKnownHostsFile /dev/null" \ -o StrictHostKeyChecking=no \ `grep hbase-master ~/.whirr/hbase-testing/instances \ | awk '{print $3}'` # Maven 2 is available through the package manager, but an incompatibility # with surefire 2.12 makes it a pain to use; here we download Maven 3 without # the OS package manager wget 'http://archive.apache.org/dist/maven/maven-3/3.0.4/binaries/apache-maven-3.0.4-bin.tar.gz' tar -xzf apache-maven-3.0.4-bin.tar.gz # Install git sudo apt-get install -y git-core # Clone JanusGraph git clone 'git://github.com/JanusGraph/janusgraph.git' && cd janusgraph # Run a HBase-backed test of JanusGraph # # This test should produce pages of output ending in something like this: # # ------------------------------------------------------- # T E S T S # ------------------------------------------------------- # Running org.janusgraph.graphdb.hbase.ExternalHBaseGraphPerformanceTest # Starting trial 1/1 # 10000 # 20000 # 30000 # 40000 # 50000 # Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 303.659 sec # # Results : # # Tests run: 1, Failures: 0, Errors: 0, Skipped: 0 # # [INFO] ------------------------------------------------------------------------ # [INFO] BUILD SUCCESS # [INFO] ------------------------------------------------------------------------ ~/apache-maven-3.0.4/bin/mvn test -Dtest=ExternalHBaseGraphPerformanceTest#unlabeledEdgeInsertion # Check on hadoop hadoop version # Should print 1.0.3 # List the hadoop root; should print something like: # # Found 4 items # drwxr-xr-x - hadoop supergroup 0 2012-09-20 00:20 /hadoop # drwxr-xr-x - hadoop supergroup 0 2012-09-20 00:42 /hbase # drwxrwxrwx - hadoop supergroup 0 2012-09-20 00:20 /tmp # drwxrwxrwx - hadoop supergroup 0 2012-09-20 00:20 /user hadoop fs -ls /
The HBase shell on the master server can be used to get an overall status check of the cluster.
$HBASE_HOME/bin/hbase shell
From the shell, the following commands are generally useful for understanding the status of the cluster.
status 'janusgraph' status 'simple' status 'detailed'
The above commands can identify if a region server has gone down. If so, it is possible to ssh into the failed region server machines and do the following:
sudo -u hadoop $HBASE_HOME/bin/hbase-daemon.sh stop regionserver sudo -u hadoop $HBASE_HOME/bin/hbase-daemon.sh start regionserver
The use of pssh can make this process easy as there is no need to log into each machine individually to run the commands. Put the IP addresses of the regionservers into a hosts.txt file and then execute the following.
pssh -h host.txt sudo -u hadoop $HBASE_HOME/bin/hbase-daemon.sh stop regionserver pssh -h host.txt sudo -u hadoop $HBASE_HOME/bin/hbase-daemon.sh start regionserver
Next, sometimes you need to restart the master server (e.g. connection refused exceptions). To do so, on the master execute the following:
sudo -u hadoop $HBASE_HOME/bin/hbase-daemon.sh stop master sudo -u hadoop $HBASE_HOME/bin/hbase-daemon.sh start master
Finally, if an HBase cluster has already been deployed and more memory is required of the master or region servers, simply edit the $HBASE_HOME/conf/hbase-env.sh files on the respective machines with requisite -Xmx -Xms parameters. Once edited, stop/start the master and/or region servers as described previous.